Intel e il nuovo 56-cores “Cascade Lake”
In tal modo il gigante di Santa Clara cercherà di opporsi all'arrivo del nuovo 64-core AMD EPYC.
Intel ha rilasciato numerose informazioni sui nuovi prodotti in uscita. Tra le novità appaiono importanti aggiornamenti della produzione relativa alla serie Xeon Scalable enterprise processor, tra cui un nuovo processore 56-cores Xeon Scalable “Cascade Lake”. L’Azienda di Santa Clara ha progettato un’intera suite di prodotti, con un occhio di riguardo all’archiviazione, alla movimentazione e all’elaborazione dei dati. Di qui il nuovo mantra Move, Store, Process, che incorpora la sua strategia end-to-end. In sede di recensione tratteremo l’offerta degli Xeon Scalable processors, mentre qui valuteremo rapidamente tutto l’insieme delle novità presentate.

Il nuovo chip potrebbe rappresentare la prima risposta della casa di Santa Clara all’arrivo del processore AMD 7nm EPYC, codename “Rome”, con 64 cores e un’interfaccia di memoria monolitica. Il modulo “Cascade Lake” a 56-cores rappresenta un dual-die multi-chip module (MCM), composto da due elementi a 28-cores, ciascuno dotato di un’interfaccia di memoria a 6 canali ddr4. In tal modo il package raggiunge un’ampiezza di 12 canali. Ciascuno dei due elementi a 28 cores utilizza un processo di fabbricazione attuale su silicio a 14 nm++, mentre il rateo IPC di ciascun core rimane sostanzialmente identico alla versione “Skylake.” Intel ha tuttavia aggiunto tutta una serie di set di istruzione diretti all’High-Performance Computing (HPC) ed all’Intelligenza Artificiale (AI).
Per iniziare, viene definito il DL Boost, apparentemente un moltiplicatore matriciale Hardware a funzione fissa che accelera la costruzione e l’apprendimento di reti neurali per progetti deep-learning di AI. Quindi abbiamo modifiche hardware contro diverse vulnerabilità di sicurezza relative ad esecuzione speculativa di codice nella CPU. Simili vulnerabilità hanno infestato il mondo dell’informatica dall’inizio del 2018. A tal riguardo restano tristemente note alcune varianti di “Spectre” e di “Meltdown“.
Ricordiamo che una correzione in hardware comporta un impatto decisamente minore sulla performance rispetto a un workaround software nella forma di una patch firmware.

Intel ha inoltre esteso la compatibilità per le sue Optane Persistent Memory. Un progetto ad ampio spettro relativo all’evoluzione del concetto di memoria primaria volatile come le DRAM.
Anche se al momento resta più lenta della DRAM classica, Optane Persistent Memory è già più veloce di sistemi di archiviazione in tecnologia SSD. Optane inoltre è non volatile (persistente), ed i suoi contenuti possono essere resi immuni e sopravvivere alle interruzioni di corrente. Un simile comportamento consentirebbe agli amministratori di sistema di spegnere completamente i server in produzione. Sarà possibile gestire le modifiche di carico senza preoccuparsi dei lunghi tempi necessari per il ripristino dell’uptime completo alla loro ripartenza.
Un ultimo particolare degno di importanza: nel set di istruzioni esteso della CPU compaiono le istruzioni vettoriali avanzate (AVX-512) e quelle relative alla crittografia (AES-NI).
Ma analizziamo più a fondo il nuovo sistema.
| Cores / Threads | Base / Boost Freq. (GHz) | L3 Cache | TDP | |
|---|---|---|---|---|
| Xeon Platinum 9282 | 56 / 112 | 2.6 / 3.8 | 77 MB | 400W |
| Xeon Platinum 9242 | 48 / 96 | 2.3 / 3.8 | 71.5 MB | 350W |
| Xeon Platinum 9222 | 32 / 64 | 2.3 / 3.7 | 71.5 MB | 250W |
| Xeon Platinum 9221 | 32 / 64 | 2.1 / 3.7 | 71.5 MB | 250W |

Appare innanzi tutto evidente come Intel abbia progettato l’intera suite di prodotti per accelerare le prestazioni orientate al data storage. Di seguito gli elementi annunciati:
- Le nuove istruzioni del processore
- Il numero impressionante di cores (e di threadas!) disponibile
- le linee di interfaccia per la memoria
- la suddivisione degli elementi interni al chip per garantire un efficiente colloquio interno
- un efficace comunicazione inter-processo
- L’utilizzo massiccio di Optane Persistent Memory
- Nuovi SSD di classe enterprise per data centre
- Nuovi controller Ethernet
- 10nm Agilex FPGA
Intel dichiara che la famiglia di processori offre la massima performance per carichi di tipo HPC, AI, e IAAS. I processori sono dotati di un imponente numero di canali di memoria per favorire l’accesso alla massima velocità. Tutto ciò evidenzia come la strategia Intel sia diretta verso una progettazione multi-chip, specialmente per la classe di modelli ad elevato numero di cores.
La serie 9200 comprende tre famiglie, con l’offerta di modelli a 56-, 48- e 32-core. Le frequenze di clock sono massime per il modello Xeon Platinum 9282 con configurazione 56-core, 3.8 GHz in boost, e velocità standard su tutti i cores ad una frequenza di 2.6 GHz. L’ammiraglia della famiglia, lo Xeon Platinum 9282, dispone anche di 77 MB di cache L3.
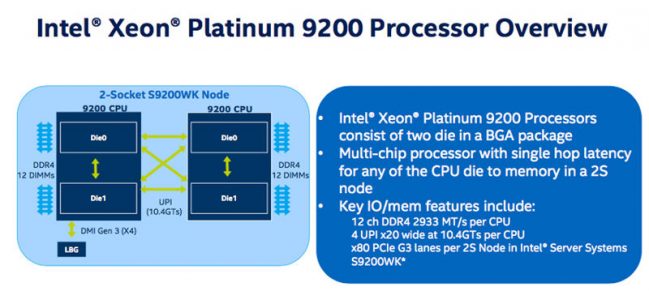
Nel particolare, ciascun processore ha al suo interno due elementi, ciascuno rappresentato da un die modificato da 28-core XCC (extreme core count). Ogni die riporta un controller di memoria a sei canali. Ciò consente al processore di gestire 12 canali di memoria DDR4-2933, garantendo sino a 24 canali di memoria e 3 TB di memoria DDR4 in un server a doppio socket. Questo significa che un server con due sockets dotato del modello a 56 cores può raggiungere un throughput di memoria pari a 407 GB/s.
Contrariamente agli altri processori della famiglia Cascade Lake, questi chips non sono compatibili con socket della generazione precedente. Al contrario, anziché essere socketed processors, i processori della serie 9200 sono distribuiti in un package BGA (Ball Grid Array). Questo risulta saldato direttamente alla motherboard ospite attraverso un’interfaccia 5903-ball.
I chip della serie 9200 rendono disponibili sino a 40 linee PCIe 3.0 per chip, per un totale di 80 linee in un server dual socket. A dire il vero, ciascun die ha a disposizione 64 linee PCIe, ma Intel riserva alcune linee per gestire il servizio di comunicazione UPI (Ultra-Path Interconnect), che collega all’interno del processore i due die, mentre altre sono dedicate alla comunicazione tra due chip in una configurazione server dual-socket. In tutto sono quindi disponibili quattro connessioni UPI per socket, con un totale di 10.4 GT/s di throughput.
Un server dual-socket si presenta così come un server quad-socket verso l’host, mostrando i quattro nodi NUMA come quattro diverse CPU. Ricordiamo come in origine le architetture NUMA rappresentavano sistemi dotati di “Non Uniform Memory Addressing”. Tuttavia la topologia dual-die presenta problemi legati alla latenza negli accesso a banchi di memoria ‘lontani’. Intel garantisce di aver ridotto il rischio che ciò avvenga con uno schema di routing a hop singolo. Un simile schema garantirebbe 79ns di latenza per le memorie ‘vicine’ e 130ns per accessi alle memorie ‘lontane’.
A questo punto sarebbe interessante capire meglio cosa significhi più esattamente latenza per la memoria ‘vicina’ e ‘lontana’. ‘Lontana’ significa sul sul die dell’altro processore, sull’altro die dello stesso processore, o entrambe le cose? O addirittura significa accedere al processore sull’altro socket? Perché ovviamente in uno dei casi presentati ci troveremmo di fronte a una “accoppiata” di processori 8180, e questo a sua volta sarebbe molto simile a una versione potenziata del modello descritto nel sistema Ryzen CCX-based die.

In conclusione, ci troviamo di fronte a una valanga di novità, tra le quali il nuovo Xeon fa la parte del leone. Tuttavia, mentre appare evidente lo sforzo di Intel nell’impedire ad altri di erodere preziose quote di mercato, risulta altre sì lampante la strategia data centric della casa di Santa Clara. La spinta della produzione in reami una volta appannaggio di Samsung, Huawei o Western Digital mette in luce ancora una volta il (grosso) problema dello sviluppo più commercial: l’utente finale avrà una qualche ricaduta tecnologica solo quando i prodotti di punta saranno diventati ordinari. Il tutto, manco a dirlo, a beneficio di AMD.
